我以前做这种项目都是用上位机来做调度的,好处是可用用配置文件或者设置界面的方式动态调整各种调度条件和需要收集的数据点。不过上位机调度需要通信时间开销,做的不好的话会有明显的等待时间,这方面需要一定的实战经验和技巧。
只靠PLC解决,主要还是把思路梳理清楚以后把调度算法抽象出来,并建立数据结构来支撑这个调度算法,包括输入的,输出的和中间变量都放到数据结构中去。最终效果就是所谓的面向对象,只要把这个对象定义清楚了,就不是什么大问题。
这里随便举个例子:
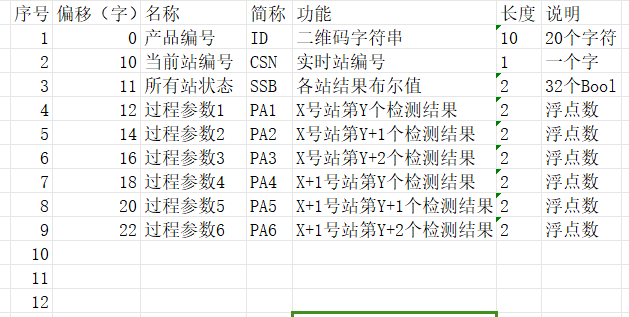
PLC的调度逻辑实际上非常简单,你这里后面没有扫描了,默认产品都是顺序流动的。用上面的数据解构建立一个先进先出的FIFO,首站上线push一个元素到FIFO中,开始往后流转,每个站触发以后在FIFO进行搜索,把FIFO中当前站号=当前站的上一站的的那个数据结构中的当前站编号字段改成本站的编号,并在加工结束后给所有站状态这个字段中代表本站的位写入结果,比如合格写1不合格写0;如果当前站 有检测结果要记录,那么写入对应的过程参数n,因为是全局的,所以把一个产品所有可能用到的参数都列出来。当一个产品依次走完所有的站后,在最后一个站检查所有站结果是不是都为1,是就报OK,不是就报NG。处理完成后(如果NG品要隔离的话),在FIFO中删除这个元素。
这个只是一种简单的搞法,实际项目会更复杂,比如说所有结果这个字段很多时候只用bool类型是不行的,即不止有好和不好,还要更细化的分类,这个时候就变通一下就行了。
你这里最大的问题是后面没有扫码了,整个产线搞成了类似多工位转盘那种思路,这就要求中间绝对不能乱,一乱了就数据和实物就对不上了,但是好处就是其实可以更简单,比如上面的FIFO,你可以不用,甚至把产品数据结构的地址定死都行,因为你的调度和工艺是严格绑定的,就长这个样子了。我们以前会在每个站都装扫码,可以在工位间随意加buffer,瓶颈工位也可以加双工位,都很简单,因为把工艺和调度解耦开了以后,就可以非常自由的进行调度了。
 沪公网安备31010802001143号
沪公网安备31010802001143号

